![[자료구조] 연결 리스트: 도입](https://cdn.hashnode.com/res/hashnode/image/upload/v1718186835151/a7bcf695-430e-4063-a97e-7d2c9c8b2f93.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


Table of contents
복잡한 프로그램을 구현하다 보면 기본적인 포인터 구조만 이용해서 메모리를 관리하기에는 다소 번거로울 때가 많다.
만약 메모리를 좀 더 효율적으로 관리하고 사용할 수 있다면 어떨까? 이를 위해 데이터 구조의 개념과 연결리스트에 대해 알아보자.
데이터 구조는 우리가 컴퓨터 메모리를 더 효율적으로 관리하기 위해 새로 정의하는 구조체이다.
일종의 메모리 레이아웃, 또는 지도라고 생각할 수 있다.
데이터 구조중 하나인 연결 리스트에 대해 알아보자.
배열에서는 각 인덱스의 값이 메모리상에서 연이어 저장되어 있다.
하지만 꼭 그럴 필요가 있을까? 각 값이 메모리상의 여러 군데 나뉘어져 있다고 하더라도 바로 다음 값의 메모리 주소만 기억하고 있다면 여전히 값을 연이어서 읽어들일 수 있다.
이를 '연결 리스트'라고 한다. 아래의 그림과 같이 크기가 3인 연결 리스트는 각 인덱스의 메모리 주소에서 자신의 값과 함께 바로 다음 값의 주소(포인터)를 저장한다.
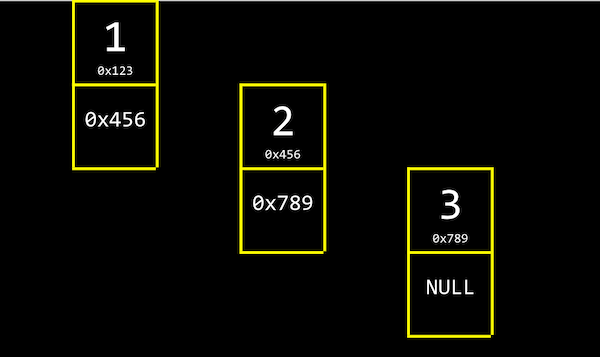
연결 리스트의 가장 첫 번째 값인 1은 2의 메모리 주소를, 2는 3의 메모리 주소를 함께 저장하고 있다.
3은 다음 값이 없기 때문에 NULL(\0, 즉 0으로 채워진 값을 의미)을 다음 값의 주소로 저장한다.
연결 리스트는 아래 코드와 같이 간단한 구조체로 정의할 수 있다.
typedef struct node
{
int number;
struct node *next;
}
node;
node라는 이름의 구조체는 number와 *next 두 개의 필드가 함께 정의되어 있다.
number는 각 node가 가지는 값, *next는 다음 node를 가리키는 포인터가 된다.
여기서 typedef struct대신에 typeof struct node라고 node를 함께 명시해 주는 것은, 구조체 안에서 node를 사용하기 위함이다.
생각해보기
연결 리스트를 배열과 비교했을 때 장단점은 무엇이 있을까?
정답
연결 리스트의 경우 리스트의 추가, 삭제가 배열에 비해 용이하다. 그러나 인덱스를 이용한 데이터 접근이 어려워 원하는 노드에 접근하기 위해 더 많은 시간이 소요된다.